LuaJIT GC64 模式
OpenResty® 使用 LuaJIT 作為主要的計算引擎,使用者也主要使用 Lua 語言來編寫應用,即使是那些非常複雜的應用。在 64 位系統(包括 x86_64)上,LuaJIT 垃圾回收器能管理的記憶體最大隻有 2GB 一直為社群所詬病。所幸 LuaJIT1 官方在 2016 年引入了 “GC64” 模式,這使得這個上限可以達到 128 TB(也就是低 47 位的地址空間),這也就意味著可以不受限制的跑在當今主流的個人電腦和伺服器上了。在過去的兩年裡,GC64 模式已經足夠成熟,所以我們決定在 x84_64 體系結構上也預設開啟 GC64 模式,就像在 ARM64(或者 AArch64)體系結構上一樣。這篇文章將簡要介紹過去老的記憶體限制原因,以及新的 GC64 模式。
老的記憶體限制
官方的 LuaJIT 在 x86_64 體系結構上預設使用 “x64” 模式2,OpenResty 1.13.6.2 之前在 x86_64 體系上也預設使用這個模式。這個模式下 LuaJIT 垃圾回收器只能使用低 31 位的地址空間,這也就意味著最多能管理 2 GB 記憶體。
何時會碰到這個記憶體限制
那麼甚麼時候會碰到這個 2 GB 的記憶體限制呢,我們很容易用一個小的 Lua 指令碼來複現
-- File grow.lua
local tb = {}
local i = 0
local s = string.rep("a", 1024 * 1024)
while true do
i = i + 1
tb[i] = s .. i
print(collectgarbage("count"), " KB")
end
這個指令碼里有一個 while 無限迴圈,不斷地建立新的 Lua 字串,並插入到一個 Lua table 裡(為了防止 Lua 垃圾回收器回收它們)。每一次迴圈迭代都會建立一個 1MB 多的 Lua 字串,並用 Lua 標準的 API 函式 collectgabarge 來輸出當前由 Lua 垃圾回收器(GC)所管理的記憶體總大小。另外,值得一提的是,頂層作用域的 Lua table 變數 tb 也會持續生長,所以也會不斷地消耗更多記憶體,雖然比那些 Lua 字串消耗的要小得多。
我們可以簡單地使用 OpenResty 提供的 resty 命令來跑這個指令碼,比如:
$ resty grow.lua
4181.08984375 KB
5205.6767578125 KB
6229.869140625 KB
6229.66796875 KB
8277.4013671875 KB
9301.5546875 KB
10325.741210938 KB
...
2003241.1367188 KB
2004265.3320313 KB
2005289.5273438 KB
2006313.7226563 KB
2007337.9179688 KB
$
這次我們使用 “x64” 模式來編譯 OpenResty。顯然,在 Lua 垃圾回收器管理的記憶體接近 2GB 的時候,resty 工具就退出了。實際上是程序崩潰了。我們可以察看 shell 的返回值:
$ echo $?
134
使用 luajit 命令來跑這個指令碼,我們可以看到更詳細的崩潰錯誤資訊:
$ /usr/local/openresty/luajit/bin/luajit grow.lua
4181.08984375 KB
5205.6767578125 KB
6229.869140625 KB
6229.66796875 KB
8277.4013671875 KB
...
2053220.5429688 KB
2054244.5634766 KB
2055268.5839844 KB
2056292.6044922 KB
2057316.625 KB
PANIC: unprotected error in call to Lua API (not enough memory)
這證實了我們確實觸及到記憶體上限。
記憶體限制是每程序的
OpenResty 繼承了 Nginx 的多程序模型來充分利用單機的多個 CPU 核,所以每個 Nginx worker 程序都有它自己獨立的地址空間。因此,這個 2 GB 的限制也只是每一個獨立的 Nginx worker 程序級別的。假如一個 OpenResty/Nginx 服務有 12 個 worker 程序的話,那麼這個總的記憶體限制將是 2 * 12 = 24 GB。這也是為甚麼這麼多年來,這個限制並沒有給大型的 OpenResty 應用帶來太多的問題,甚至大部分的 OpenResty 使用者還不知道有這個限制。
然而,這個記憶體限制並不是每 LuaJIT 虛擬機器(VM)級別的。比如,同一個 Nginx 程序內,ngx_stream_lua_module 和 ngx_http_lua_module 都建立了他們自己的 LuaJIT VM 例項,但是並不意味著這兩個 LuaJIT VM 分別可以最多管理 2GB 記憶體,而是這兩個 LuaJIT VM 加起來最多管理 2GB 的記憶體。因為這個記憶體限制是受限於地址空間,LuaJIT 的 GC 管理器只能使用低 31 位的地址空間。這個地址空間是程序級別的。
GC 管理的記憶體
大多數的 Lua 層面的物件(比如,string、table、fucntion、userdata、cdata、thread、trace、upvalue 和 prototype)都是為 LuaJIT 的垃圾回收器(GC)所管理的。其中的 upvalue 和 prototype 物件一般為 function 物件所引用。這些都被統稱為 “GC 物件”。
其他原始值,比如 number,boolean 和 light userdata 並不是被 GC 管理的。他們直接使用真實的值作來編碼,在 LuaJIT 內部被稱作 “TValue”(或者 tagged values)。在 LuaJIT 內部,TValue 總是 64 位的,即使是單精度浮點數也是 64 位的(LuaJIT 使用了 “NAN tagging” 的技術來實現如此的高效的)。這也是為甚麼通常情況下,同一個應用使用 LuaJIT 來執行,會比使用標準的 Lua 5.1 直譯器來執行所佔用的記憶體少很多3。
不由 GC 管理的記憶體
LuaJIT 的 cdata 資料型別比較特殊。如果是透過標準的 LuaJIT API 函式 ffi.new() 來建立的 cdata 物件,他是由 GC 來管理的。但是如果是透過 C 層面函式,比如 malloc() 和 mmap(),或者其他的 C 庫函式來申請的記憶體,那麼這些記憶體 不是 由 GC 管理的,也就不會受到這個 2 GB 的限制。我們可以用如下的 Lua 指令碼來測試:
-- File big-malloc.lua
local ffi = require "ffi"
ffi.cdef[[
void *malloc(size_t size);
]]
local ptr = ffi.C.malloc(5 * 1024 * 1024 * 1024)
print(collectgarbage("count"), " KB")
這裡我們使用 ffi 呼叫了標準的 C 庫函式 malloc() 來申請 5 GB 的記憶體塊,使用 “x64” 模式的 OpenResty 或者 LuaJIT 來執行這個指令碼並不會崩潰。
$ resty big-malloc.lua
73.1298828125 KB
GC 管理的記憶體大小也只有 73 KB,很明顯沒有包括直接從系統申請的 5 GB 記憶體塊。
然而,不被 GC 管理的記憶體也可能對 LuaJIT 的記憶體限制產生不利影響。這是為甚麼呢?因為這些記憶體也可能會在低 31 位的空間內。
在 Linux x86_64 系統上執行 mmap() 系統呼叫的時候,如果沒有指定任何地址引數(或其他會影響到記憶體分配地址的引數),一般並不會使用到低 31 位的地址空間。然而使用像 sbrk() 這類的呼叫則幾乎總是優先使用低地址空間。後者就會讓 LuaJIT 的 GC 記憶體分配器所能使用的記憶體空間又縮小了。這是由 Linux 等作業系統的記憶體佈局方式決定的:“堆” 總是從低位到高位向上生長。類似地,在 Linux 等系統上,程式的資料段總是使用低地址空間靠近起始的位置,所以資料段內的靜態常量資料(比如常量 C 字串的值)也會進一步擠壓 LuaJIT 可用的低地址空間。
基於上述原因,在 x86_64 體系下,實際可供 LuaJIT 使用的地址空間可能還顯著小於 2 GB。實際可用的空間大小,取決於應用程式自身具體在甚麼地址位置上,申請了多少數量的記憶體空間。社群的使用者也曾向我們反饋過這樣的問題:在 FreeBSD 上,Nginx 申請的共享記憶體區域4也會擠壓 LuaJIT 能使用的低地址空間。另外也有使用者報告說,當使用了 ngx_http_slice_module 這樣的第三方模組的時候,LuaJIT 也更容易丟擲記憶體不足的異常。
提升 x64 模式的記憶體上限到 4 GB
理論上來說,LuaJIT 在 x64 模式上的上限應該是 4 GB(也就是低 32 位地址空間)而不是 2 GB,而且在 i386 系統上 LuaJIT 也確實能充分利用低地址的 4GB 空間。因為 LuaJIT 內部的手寫彙編程式碼,每當需要從 32 位地址指標值轉換到 64 位的時候,都需要正確處理“符號位擴充套件”(sign extension)的問題,也就導致了這個上限只有 2 GB。而 i386 體系則不存在這個問題,因為一個 word 值始終是 32 位的。
儘管 4 GB 比 2 GB 大了一倍,不過還是有可能觸發上述那些問題。所以 LuaJIT 的開發者決定開發一個新的 VM 模式,以便能夠使用到 大得多 的地址空間,於是便誕生了 GC64 模式。值得一提的是,這個 GC64 模式也是 ARM64(Aarch64)體系結構上的唯一選擇,因為在那裡低地址空間很難申請到。
新的 GC64 模式
GC64 模式始於 2016 年,最先由 Peter Cawley 實現,然後由 Mike Pall 來整合。在過去的兩年多里,已經修復了很多 bug,並且經過廣泛的測試,證明它已經足夠穩定用於生產環境了,所以 OpenResty 也將在 x86_64 體系上切換到這個新的 GC64 模式 (ARM64 上已經強制使用 GC64 模式了)。
在 GC64 模式下,原始的 Lua 變數(上面提到的 TValue)還是繼續保持 64 位大小,我們不用擔心新的模式下記憶體使用量會有明顯的漲幅。但是,還是有一些資料型別會變大(從 32 位變成 64 位),比如 MRef 和 GCRef 這樣的在 LuaJIT 內部很常見的 C 資料型別。所以,GC64 模式下,儘管記憶體佔用不會多很多,但肯定會更大一些。
在 GC64 模式下,垃圾回收管理器已經能使用低 47 位地址空間,也就是 128 TB。這已經遠超當今高階 PC 機的實體記憶體(通常 64GB 就可以算大記憶體的機器,AWS EC2 例項最大的記憶體也只有 12 TB)。這也意味著,GC64 模式在當今的現實世界裡,其實算是沒有記憶體限制。
如何開啟 GC64 模式
如果從 LuaJIT 原始碼編譯,可以這樣開啟5:
make XCFLAGS='-DLUAJIT_ENABLE_GC64'
如果從 1.13.6.2 版本 之前 的 OpenResty 原始碼安裝,可以在 ./configure 指令碼加上如下選項來開啟:
-with-luajit-xcflags='-DLUAJIT_ENABLE_GC64'
從 OpenResty 1.15.8.1 開始已經預設在 x86_64 系統上開啟 GC64,包括 OpenResty 官方提供的二進位制包 也預設開啟了。
效能影響
新的 GC64 模式將產生多大的影響呢,下面用我們的一些大 Lua 程式來測試一下
Edge 語言編譯器
首先,我們使用 Edge 語言(也叫 “edgelang”)編譯器來編譯一些大的 WAF 模組,在 x64 模式下:
$ PATH=/opt/openresty-x64/bin:$PATH /bin/time ./bin/edgelang waf.edge >
/dev/null
0.73user 0.03system 0:00.77elapsed 99%CPU (0avgtext+0avgdata 119660maxresident)k
0inputs+0outputs (0major+33465minor)pagefaults 0swaps
用 edgelang 編譯器把 waf.edge 編譯為 Lua 程式碼,花費了 0.73s 的使用者態時間,最大記憶體佔用是 119660 KB,也就是 116.9MB。下面我們用 GC64 模式:
$ PATH=/opt/openresty-plus-gc64/bin:$PATH /bin/time ./bin/edgelang waf.edge
> /dev/null
0.70user 0.03system 0:00.74elapsed 99%CPU (0avgtext+0avgdata 133748maxresident)k
0inputs+0outputs (0major+35396minor)pagefaults 0swaps
最大記憶體佔用是 133748 KB,也就是 130.6MB,只大了 11.1%。CPU 使用時間幾乎是一樣的,這一點區別可以當做測試誤差。
Edge 語言編譯器是基於 OpenResty 上純 Lua 的實現,包括空行和註釋一共有 83,315 行程式碼,兩者模式下對應的 LuaJIT 位元組碼都是 1.8MB(儘管 x64 和 GC64 的位元組碼不相容)。
Y 語言編譯器
我們再試一下 Y 語言(也叫做 ylang)編譯器,這也是基於 OpenResty 的純 Lua 命令列程式。
ylang 編譯器比 edgelang 編譯器要更大一些,對應的 LuaJIT 位元組碼有 2.1 MB(兩個模式都是)。
我們先用 x64 模式,把 ljfrace.y 工具編譯為 systemtap+ 指令碼:
$ PATH=/opt/openresty-x64/bin:$PATH /bin/time ./bin/ylang --stap --symtab
luajit.jl lftrace.y > /dev/null
1.30user 0.12system 0:01.42elapsed 99%CPU (0avgtext+0avgdata 401184maxresident)k
0inputs+240outputs (0major+116438minor)pagefaults 0swaps
花了 1.3s 的使用者態時間,最多佔用了 401184 KB 記憶體,下面試一下 GC64 模式:
$ PATH=/opt/openresty-gc64/bin:$PATH /bin/time ./bin/ylang --stap --symtab
luajit.jl lftrace.y > /dev/null
1.30user 0.11system 0:01.42elapsed 99%CPU (0avgtext+0avgdata 433948maxresident)k
0inputs+240outputs (0major+125591minor)pagefaults 0swaps
還是花了 1.3s 時間,以及 433948 KB。這次時間沒有區別,記憶體也只多佔用了 8.2%。
除錯分析工具鏈
目前開源的動態分析工具,包括 openresty-systemtap-toolkit, stap++ 和 openresty-gdb-toolkit 幾乎都不支援新的 GC64 模式,我們也不再維護這些針對 systemtap 和 gdb 的開源工具了。 我們的重心已經放到了 OpenResty XRay 平臺及其 Y 語言編譯器上。我們用標準 C 語言的超集(即 Y 語言)編寫工具。Y 語言編譯器可以將其編譯為 Python 程式碼,並執行在 gdb 裡,也可以編譯為 stap+ 指令碼用 systemtap+6 來執行(未來也會支援更多的後端,可以執行在更多的除錯和動態追蹤平臺上)。我們幾乎不用改動這些 Y 語言編寫的工具,就可以直接支援 GC64 模式。這個得益於智慧化的除錯資訊處理,以及 Y 語言使用的是 C 語言層面的表達方式。
如下是一個 GC64 模式下的 Openresty Lua 層面的火焰圖,使用的是我們的 ylang 工具和 systemtap+。
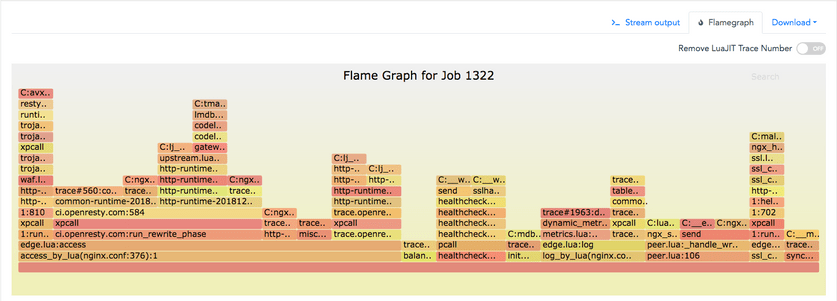
並且 ylang 編譯器生成的 gdb 工具也可以用於分析 core dump 檔案,比如:
(gdb) lbt 0 full
[builtin#128]
exit
test.lua:16
c = 3
d = 3.140000
e = true
k = nil
null = light userdata (void *) 0x0
test.lua:baz
test.lua:19
ffi = table: (GCtab *)\E0x[0-9a-fA-F]+\Q
cjson = table: (GCtab *)\E0x[0-9a-fA-F]+\Q
test.lua:0
ffi = table: (GCtab *)\E0x[0-9a-fA-F]+\Q
cjson = table: (GCtab *)\E0x[0-9a-fA-F]+
C:pmain
(gdb)
火焰圖裡的函式幀包含了 Lua 函式幀和 C 函式幀。
我們在 OpenResty XRay 裡不僅提供了現成的基於 ylang 編寫的動態追蹤分析工具,也提供了線上編譯器。我們可以使用 Y 語言輕鬆實現全新的分析工具。
LuaJIT 內建的效能分析器
從 2.1 版本開始,LuaJIT 官方就內建了虛擬機器層面的效能分析器。這個自然可以繼續在 GC64 模式下使用。然而,不同於 systemtap+ 這樣的系統層面的動態追蹤工具,它必須清空所有已經 JIT 編譯過的 Lua 程式碼(在 LuaJIT 的術語裡叫 “traces”),並且需要用特殊的效能分析模式重新進行 JIT 編譯。因此,每次開啟和關閉效能分析器,都會觸發所有相關 Lua 程式碼重新開始 JIT 編譯。這必然會修改當前程序裡的很多狀態(很容易有意外的副作用,或者極端 bug 的出現),並且在分析取樣期間,也會有較高的效能損耗7。另外,目標 Lua 程式也需要提供一個特殊的 API 或者鉤子來觸發這樣的效能分析模式,因此需要應用程式的專門配合,才能讓內建效能分析器正確工作。然而,基於動態追蹤技術的效能分析則完全無需 Lua 應用程式的任何配合,甚至不需要重啟,或者使用特殊的編譯選項。
結論
文字介紹了 LuaJIT 新的 GC64 模式,可以有效地取消原先 2GB 每程序的 GC 管理的記憶體上限。使用更多的記憶體的能力也意味著 OpenResty 應用自己需要更加小心記憶體使用量過大或記憶體洩漏之類的問題。幸運的是,OpenResty XRay 可以幫助我們快速分析和最佳化任意的 OpenResty 應用的記憶體使用。我們在一個新的系列文章中將會展開這個話題。
延伸閱讀
關於 OpenResty XRay
OpenResty XRay 是由 OpenResty Inc. 公司提供的商業產品。我們使用此產品為我們的文章(比如本文)提供直觀的圖表演示和真實系統內部的統計資料。OpenResty XRay 可以在無需目標程式任何配合的情況下,幫助使用者深入洞察其線上或者線下的各種軟體系統的行為細節,有效地分析和定位各種效能問題、可靠性問題和安全問題。
有興趣的朋友歡迎聯絡我們,申請免費試用。
關於作者
章亦春是開源 OpenResty® 專案創始人兼 OpenResty Inc. 公司 CEO 和創始人。
章亦春(Github ID: agentzh),生於中國江蘇,現定居美國灣區。他是中國早期開源技術和文化的倡導者和領軍人物,曾供職於多家國際知名的高科技企業,如 Cloudflare、雅虎、阿里巴巴, 是 “邊緣計算“、”動態追蹤 “和 “機器程式設計 “的先驅,擁有超過 22 年的程式設計及 16 年的開源經驗。作為擁有超過 4000 萬全球域名使用者的開源專案的領導者。他基於其 OpenResty® 開源專案打造的高科技企業 OpenResty Inc. 位於美國矽谷中心。其主打的兩個產品 OpenResty XRay(利用動態追蹤技術的非侵入式的故障剖析和排除工具)和 OpenResty Edge(最適合微服務和分散式流量的全能型閘道器軟體),廣受全球眾多上市及大型企業青睞。在 OpenResty 以外,章亦春為多個開源專案貢獻了累計超過百萬行程式碼,其中包括,Linux 核心、Nginx、LuaJIT、GDB、SystemTap、LLVM、Perl 等,並編寫過 60 多個開源軟體庫。
關注我們
如果您喜歡本文,歡迎關注我們 OpenResty Inc. 公司的部落格網站 。也歡迎掃碼關注我們的微信公眾號:

譯文
我們提供了英文版原文和中譯版(本文) 。我們也歡迎讀者提供其他語言的翻譯版本,只要是全文翻譯不帶省略,我們都將會考慮採用,非常感謝!
OpenResty 維護了我們自己的分支,這個分支裡包含了一些高階特性以及針對 OpenResty 的特殊最佳化,這個分支會定期的從 官方 LuaJIT 同步。 ↩︎
從 2019 年 12 月 8 日開始,官方的 LuaJIT 也開始在 x86_64 系統上預設使用 GC 模式。 ↩︎
我們曾在真實的生產環境,觀察到 LuaJIT 與標準 Lua 5.1 直譯器之間的記憶體使用量,存在成倍的差別。 ↩︎
這些共享記憶體區域實際上是透過
mmap系統呼叫分配的。 ↩︎從 2019 年 12 月 8 日開始,官方 LuaJIT 在 x86_64 上已預設開啟 GC64 模式。 ↩︎
systemtap+ 是由 OpenResty Inc. 大大增加和最佳化過的 systemtap。 ↩︎
Java 世界的 BTrace 工具也有類似的問題和侷限。 ↩︎
相關文章
OpenResty XRay Aug 4, 2020

OpenResty XRay Jan 21, 2020

OpenResty XRay Nov 19, 2020

OpenResty XRay Aug 10, 2020

OpenResty XRay Dec 4, 2025












