The LuaJIT GC64 Mode
OpenResty® uses LuaJIT for its main computing
engine, and
users
mainly use the Lua programming language to write applications atop OpenResty,
sometimes very complex ones. For years, there has been a notorious hard
limit in the maximum memory size managed by LuaJIT’s garbage collector
(GC). This limit was 2 GB on 64-bit systems (including x86_64). Fortunately,
since 2016, the official LuaJIT1 has introduced a new build mode
called “GC64”, which raises this limit to 128 TB (or the low 47-bit address
space). Effectively, this translates to no limit for almost all the PCs
and servers in the
market nowadays. Over the two years, the GC64 mode has matured enough and
starting from the OpenResty 1.15.8.1 release,
we enable this
by default on the x86_64 architectures, just like the ARM64 (or AArch64)
architecture. This article will provide an overview of the old memory limit
as well as an explanation of the new GC64 mode.
The Old Memory Limit
By default, the official LuaJIT uses the so-called “x64” build mode on
x86_64 systems1. This “x64” build mode is also used by default in OpenResty
releases before 1.13.6.2 on x86_64. With this mode, LuaJIT can only use
memory address values in the low 31 bit address space for the memory
managed by the garbage collector (GC).This effectively limits such memory
to the total value of 231 bytes, or 2 GB.
When Hitting The Memory Limit
What is it like when hitting the 2 GB limit? It is easy to use a simple Lua script to find out.
-- File grow.lua
local tb = {}
local i = 0
local s = string.rep("a", 1024 * 1024)
while true do
i = i + 1
tb[i] = s .. i
print(collectgarbage("count"), " KB")
end
This script has an infinite while loop which simply keeps allocating
new Lua strings and inserting them into the Lua table (in order to prevent
the GC from collecting them). Each loop iteration creates a new Lua string
of approximately 1 MB and outputs the total size of GC-managed memory via
the standard
Lua API function collectgabarge.
One thing to note here is that the Lua table associated with the top-level
Lua variable tb will also keep growing, thus taking more and more memory
itself, albeit at a much slower pace than the memory occupied by newly
allocated
Lua strings.
To run this Lua script, we can simply invoke the resty command-line utility shipped with OpenResty, like below:
$ resty grow.lua
4181.08984375 KB
5205.6767578125 KB
6229.869140625 KB
6229.66796875 KB
8277.4013671875 KB
9301.5546875 KB
10325.741210938 KB
...
2003241.1367188 KB
2004265.3320313 KB
2005289.5273438 KB
2006313.7226563 KB
2007337.9179688 KB
$
In this run, we used the x64 build of OpenResty. Apparently, the resty
utility
quits after the GC-managed memory size approaches 2 GB. The process
actually crashed:
$ echo $?
134
Using the luajit command-line utility can give us more details about
the crash:
$ /usr/local/openresty/luajit/bin/luajit grow.lua
4181.08984375 KB
5205.6767578125 KB
6229.869140625 KB
6229.66796875 KB
8277.4013671875 KB
...
2053220.5429688 KB
2054244.5634766 KB
2055268.5839844 KB
2056292.6044922 KB
2057316.625 KB
PANIC: unprotected error in call to Lua API (not enough memory)
Thus this is the proof that we are indeed hitting the memory limit.
The Memory Limit Is Per Process
OpenResty inherits Nginx’s multiple process model to utilize multiple CPU
cores in a single operating system. So each Nginx worker process has its
own address space. Thus, the 2 GB memory limit on x86_64 when using the
default x64 build of LuaJIT only applies to each individual Nginx worker
process. In the case of 12 workers in a single OpenResty or Nginx server
instance,
the total memory limit across all the worker processes would be 2 * 12 = 24 GB. This is why the 2 GB memory limit does not cause too many troubles
over the years for large OpenResty applications running on powerful machines.
Most OpenResty users are not even aware of this limitation.
The memory limit is not per LuaJIT virtual machine (VM) instance. For example, ngx_stream_lua_module and ngx_http_lua_module both create their own LuaJIT VM instances, even when sharing the same Nginx server instance. But the 2G memory limit applies to the whole process, no matter how many LuaJIT VM instances are created inside it. This is because the memory limit also has restrictions on the address space. The memory addresses have to be in the low 31 bit space.
GC-Managed Memory
Most of the standard Lua-land value objects (e.g., strings, tables, functions, userdata, cdata, threads, traces, upvalues, and prototypes) are managed by the GC. Upvalues and prototypes are associated with functions. These composite objects are also called “GC objects”.
Primitive values like numbers, booleans, and light userdata values are not managed by the GC. They are simply encoded as literal values, which are called “TValue” (or tagged values) in the LuaJIT internals. TValues are always 64-bit wide in LuaJIT, including double-precision floating-point numbers (LuaJIT uses the “NaN tagging” trick to achieve such efficiency). This is also one of the reasons that a Lua application usually uses significantly less memory with LuaJIT than with the standard Lua 5.1 interpreter2.
Memory Allocated Outside GC
LuaJIT’s cdata data type is a bit special. If the memory associated by
a cdata object is allocated by the standard LuaJIT Lua API function ffi.new(),
then it is still managed by the GC. On the other hand, if the memory is
allocated by C-land routines like malloc() and mmap(), or other external
C library functions, then such memory blocks are not managed by the GC,
and are not subject to the memory limit. For instance, consider the following
simple Lua script:
-- File big-malloc.lua
local ffi = require "ffi"
ffi.cdef[[
void *malloc(size_t size);
]]
local ptr = ffi.C.malloc(5 * 1024 * 1024 * 1024)
print(collectgarbage("count"), " KB")
Here, we call the standard C library function malloc() to allocate a
5
GB memory block via the standard LuaJIT ffi library. Running this script
with
a x64 build of OpenResty or LuaJIT does not produce any crashes:
$ resty big-malloc.lua
73.1298828125 KB
The GC-managed memory size is merely 73 KB, excluding the 5 GB memory block we allocated using the system allocator.
However, non-GC-managed memory may still affect the memory limit of LuaJIT adversely. Why? Because it matters a lot whether the externally allocated memory blocks fall inside or outside the low 31 bit address space.
When using the mmap()system call on Linux x86_64 systems without specifying
address hints (nor any other flags set which can affect
the memory block locations), it is seldom to have memory blocks returned
in the low 31 bit address space. Whereas, the memory blocks allocated by
thesbrk() calls or alike on Linux x86_64 will almost always return
an address in the low address space, thus squeezing available memory space
for new LuaJIT GC-initiated allocations. This is due to how the “heap”
grows
according to the Linux memory layout: the “program break” moves from low
to high addresses, this how the “data segment” grows on Linux
and also quite some other operating systems. Similarly, huge static
values in the data segment (such as constant C string values),
will also squeeze the available low address space since the data segment
is near the beginning of the low address space on Linux and etc.
For all the reasons mentioned above, the actual memory limit could be way
smaller than 2 GB on x86_64, depending on how much and where the rest
of the application is allocating memory. We’ve seen reports from community
users that on FreeBSD, the shared memory zones allocated by Nginx3 squeezed the available
memory space for LuaJIT. There are also reports that using memory-intensive
Nginx modules like ngx_http_slice_module
more easily triggers the memory limit panic.
Extending The x64 Mode to The 4 GB Limit
The theoretical memory limit for the existing x64 mode of LuaJIT is actually
4 GB (or 32 bit) instead of 2 GB. The same LuaJIT VM can utilize the full
low 4 GB address space on i386 systems anyway. The practical limit, however,
is lowered to 2 GB, because
the hand-crafted assembly code in the LuaJIT VM has yet to take into
account the sign extension semantics (from 32-bit pointer values to 64-bit
ones) on x86_64 CPUs. It is not a problem on i386 since the word size
is 32-bit anyway.
While 4 GB is already 2 times better than 2 GB, it still suffers limitations and all the pitfalls mentioned above. The LuaJIT developers decided that it would be much more beneficial to introduce a new VM which supports way bigger address spaces, hence the GC64 build mode. This is also the only choice on certain CPU architectures like ARM64 where the low address space cannot be (easily) preserved.
The New GC64 Mode
The development work of the new GC64 build mode of LuaJIT started in 2016.
It was pioneered by Peter Cawley and consolidated by Mike Pall.
Over the past 2 years or so, a lot of bugs have been fixed in the GC64
mode
and our recent extensive testings show that it is already mature enough
for our own production use. It is thus natural to move onto the new GC64
mode for OpenResty on x86_64 architectures (it is already
mandatory on ARM64).
The primitive Lua value representation (called “TValue” as mentioned above)
is still 64 bit in the GC64 mode, just like the old x64 mode. So we
wouldn’t expect a noticeable increase in memory usage when switching over
to the
new mode. However, there are still some data value types getting larger
(from 32 bit to 64 bit), like the C data type MRef and GCRef, commonly
used inside the LuaJIT internals. Therefore, the memory footprint may
get a bit larger for the same Lua application, though not much.
In the GC64 mode, the GC-managed memory addresses can now extend to the low 47 bit space, which is 128 TB, way more than the total physical memory available on most (if not all) of the high end machines nowadays (mainstream consumer PC motherboard still maxes out at 64 GB as of today, and the largest “high memory” AWS EC2 instance only gets 12 TB of RAM). It is therefore safe to say that there is realistically no GC-managed memory limit in the real world with the GC64 mode.
How to Enable The GC64 Mode
To enable the GC64 mode in LuaJIT, one should build LuaJIT from source like this4:
make XCFLAGS='-DLUAJIT_ENABLE_GC64'
When building OpenResty from source before the 1.13.6.2 release (inclusive),
we can add the following option to the ./configure script of OpenResty:
-with-luajit-xcflags='-DLUAJIT_ENABLE_GC64'
Later OpenResty releases will include this option on x86_64 systems by
default, including the binary pre-built packages
for OpenResty.
Performance Impact
To see how large the impact the new GC64 mode will make is in the wild, let’s do some simple experiments with some of our large Lua programs.
The Edge Language Compiler
Let’s try our Edge language (or “edgelang”) compiler to compile some large input for a web application firewall (WAF) module. For the x64 mode:
$ PATH=/opt/openresty-x64/bin:$PATH /bin/time ./bin/edgelang waf.edge >
/dev/null
0.73user 0.03system 0:00.77elapsed 99%CPU (0avgtext+0avgdata 119660maxresident)k
0inputs+0outputs (0major+33465minor)pagefaults 0swaps
To compile the waf.edge input file into Lua code with the edgelang
compiler, it takes 0.73 seconds of userland CPU time and the maximum resident
memory size used by this run is 119660 KB, or about 116.9 MB. Now let’s
try the GC64 mode of LuaJIT with the same command:
$ PATH=/opt/openresty-plus-gc64/bin:$PATH /bin/time ./bin/edgelang waf.edge
> /dev/null
0.70user 0.03system 0:00.74elapsed 99%CPU (0avgtext+0avgdata 133748maxresident)k
0inputs+0outputs (0major+35396minor)pagefaults 0swaps
This time the max resident memory size is 133748 KB, or about 130.6 MB. Only 11.1% larger. The CPU time is almost the same; the difference is within the measurement error range.
The Edge language compiler is in pure Lua targeting the OpenResty platform. It is a large program of 83,315 lines of code, including comments and empty lines. The corresponding LuaJIT byte code file is 1.8 MB for both GC64 and x64 modes of LuaJIT, though the bytecode is incompatible between these 2 different build modes.
The Y Language Compiler
We then try the Y language (or “ylang”) compiler which is also a big Lua command-line program targeting the OpenResty platform.
The ylang compiler is even bigger than the edgelang compiler we discussed
earlier. The LuaJIT byte code is 2.1 MB in size (also for both the x64
and GC64 build modes of LuaJIT). For the x64 build mode, we experiment
compiling the ljftrace.y tool into a systemtap+ script:
$ PATH=/opt/openresty-x64/bin:$PATH /bin/time ./bin/ylang --stap --symtab
luajit.jl lftrace.y > /dev/null
1.30user 0.12system 0:01.42elapsed 99%CPU (0avgtext+0avgdata 401184maxresident)k
0inputs+240outputs (0major+116438minor)pagefaults 0swaps
It takes 1.30 seconds of userland CPU time and 401184 KB of maximum resident memory. Now for the GC64 mode:
$ PATH=/opt/openresty-gc64/bin:$PATH /bin/time ./bin/ylang --stap --symtab
luajit.jl lftrace.y > /dev/null
1.30user 0.11system 0:01.42elapsed 99%CPU (0avgtext+0avgdata 433948maxresident)k
0inputs+240outputs (0major+125591minor)pagefaults 0swaps
This time, it still takes 1.30 seconds of user CPU time and 433948 maximum resident memory. The CPU time difference is zero. And the memory footprint is merely 8.2% larger.
Debugging and Profiling Tool Chains
The open source dynamic tracing and debugging tools in the openresty-systemtap-toolkit, stap++, and openresty-gdb-toolkit have little to none support for the new GC64 mode. We no longer maintain these open source tools for GDB and SystemTap. Our focus has been on the proprietary ylang compiler which can compile tools written in a superset of the standard C language (called ylang) down to both gdb tools in Python and systemtap+5 tools in systemtap’s scripting language (more backends are also coming). With ylang, we get almost immediate GC64 support once we write the various dynamic tracing tools, thanks to the intelligent debuginfo and C source code level support in ylang.
Below is a Lua-land CPU flame graph we obtained using our ylang tools via systemtap+, with a GC64 build of OpenResty:
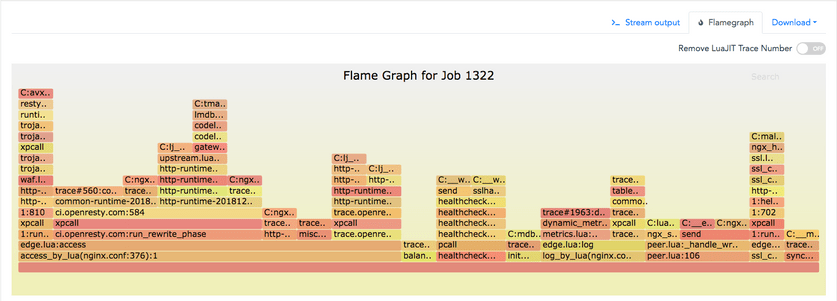
And the gdb scripts generated from these ylang tools are also usable in gdb when analyzing core dump files, as in
(gdb) lbt 0 full
[builtin#128]
exit
test.lua:16
c = 3
d = 3.140000
e = true
k = nil
null = light userdata (void *) 0x0
test.lua:baz
test.lua:19
ffi = table: (GCtab *)\E0x[0-9a-fA-F]+\Q
cjson = table: (GCtab *)\E0x[0-9a-fA-F]+\Q
test.lua:0
ffi = table: (GCtab *)\E0x[0-9a-fA-F]+\Q
cjson = table: (GCtab *)\E0x[0-9a-fA-F]+
C:pmain
(gdb)
The function frames in this flame graph are both for Lua function frames and C function frames.
We provide the ylang compiler as well as various standard tracing and profiling tools as part of the OpenResty XRay platform.
LuaJIT’s Built-in Profiler
Starting with version 2.1, the official LuaJIT comes with a built-in profiler implemented inside the virtual machine (VM). This will certainly keep working in the GC64 mode. This profiler should not be used in online profiling, however, because unlike profiling based on system-level tools like systemtap+, it has to wipe out all the existing compiled Lua code (or “traces” in LuaJIT’s terminology) and re-compile everything from scratch in a profiling-specific way. This must happen both when the profiler is turned on and off. Doing this definitely changes a lot of the state in the target process (vulnerable to unexpected side effects and corner-case bugs), and adds quite some extra overhead during the sampling window6. Besides, the target Lua application has to provide special APIs or hooks to trigger such sampling actions. Application-side collaborations are always required for this built-in profiler to work. On the other hand, profiling based on dynamic tracing tools do not need any collaborations from the Lua applications’ side, not even special build options.
Conclusion
This article explains the new GC64 mode of LuaJIT, which effectively lifts the 2GB limit on GC-managed memory in OpenResty applications. However, large memory usage and memory leaks can become a more threatening problems in some buggy OpenResty applications than ever. Fortunately, OpenResty XRay can effectively help the users analyze and optimize memory usage issues in their Openresty applications. We also just started a new series of articles expand our discussion on this topic in great detail.
Further Readings
A Word on OpenResty XRay
OpenResty XRay is a commercial product offered by OpenResty Inc. We use this product in our articles like this one to intuitively demonstrate implementation details, as well as statistics about real-world applications and open-source software. In general, OpenResty XRay can help users to get deep insight into their online and offline software systems without any modifications or any other collaborations, and efficiently troubleshoot really hard problems for performance, reliability, and security. It utilizes advanced dynamic tracing technologies developed by OpenResty Inc. and others.
You are welcome to contact us to try out this product for free.
About The Author
Yichun Zhang (Github handle: agentzh), is the original creator of the OpenResty® open-source project and the CEO of OpenResty Inc..
Yichun is one of the earliest advocates and leaders of “open-source technology”. He worked at many internationally renowned tech companies, such as Cloudflare, Yahoo!. He is a pioneer of “edge computing”, “dynamic tracing” and “machine coding”, with over 22 years of programming and 16 years of open source experience. Yichun is well-known in the open-source space as the project leader of OpenResty®, adopted by more than 40 million global website domains.
OpenResty Inc., the enterprise software start-up founded by Yichun in 2017, has customers from some of the biggest companies in the world. Its flagship product, OpenResty XRay, is a non-invasive profiling and troubleshooting tool that significantly enhances and utilizes dynamic tracing technology. And its OpenResty Edge product is a powerful distributed traffic management and private CDN software product.
As an avid open-source contributor, Yichun has contributed more than a million lines of code to numerous open-source projects, including Linux kernel, Nginx, LuaJIT, GDB, SystemTap, LLVM, Perl, etc. He has also authored more than 60 open-source software libraries.
Translations
We provided a Chinese translation for this article. We also welcome interested readers to contribute translations in other natural languages as long as the full article is translated without any omissions. We appreciate all the hard work from all our contributors.
We are hiring
We always welcome talented and enthusiastic engineers to join our team at OpenResty Inc.
to explore various open source software’s internals and build powerful analyzers and
visualizers for real world applications built atop the open source software. If you are
interested, please send your resume to talents@openresty.com . Thank you!
OpenResty bundles its own branch of LuaJIT with more advanced features and special optimizations for OpenResty. This branch still periodically synchronize latest changes from the official LuaJIT. ↩︎ ↩︎
We used to observe about 50% reduction in memory usage of real production OpenResty applications after switching from the standard Lua 5.1 interpreter over to LuaJIT 2. ↩︎
These shm zones are essentially allocated through the
mmapsystem call. ↩︎Since December 8, 2019, the official LuaJIT also enables the GC64 mode on x86_64 by default. ↩︎
systemtap+ is a greatly enhanced and optimized version of systemtap, developed inside OpenResty Inc. ↩︎
The BTrace tool in the Java world also suffers from similar problems and restrictions. ↩︎
Related Articles
OpenResty XRay Jan 21, 2020

OpenResty XRay Dec 4, 2025

OpenResty XRay Aug 10, 2020

OpenResty XRay Aug 4, 2020

OpenResty XRay Jan 13, 2026










