OpenResty Edge Design Notes: Bringing Global Traffic Scheduling Back to the Application Layer
As internet architecture has evolved, the complexity of the application layer has long since risen exponentially. However, Global Server Load Balancing (GSLB), which sits at the very front end, still seems to operate with core logic from a decade ago. GSLB (Global Server Load Balancing), which dynamically resolves DNS to direct user requests to the optimal node, is a critical technology for large-scale services to ensure an optimal user experience.
Traditional GSLB primarily focuses on “network connectivity” and “geographical proximity,” which might have been sufficient in the era of static web pages. However, in today’s landscape, dominated by dynamic content and significant computational power disparities, merely relying on network-layer ICMP or TCP handshakes to assess a node’s load capacity is akin to scratching an itch through a boot (i.e., a futile and ineffective effort). This architectural mismatch leaves us with no real-time feedback loop, forcing us to fall back on manual intervention — “human ops” — whenever traffic spikes hit. The real fix is to bring scheduling decisions back to the business itself: dynamically redistributing traffic across different machines, and even across different clusters, based on custom business metrics such as machine load and request rate.
This highlights a classic operational scenario: On the monitoring dashboard, the CPU load of an edge node shows an abnormal spike, rising far beyond expectations. Following the standard playbook, you log into the DNS console and adjust the traffic weight for that node from 80 down to 60. Due to TTL, the traffic curve only begins to slowly recede after more than ten minutes. However, this delayed “braking” causes another node to trigger an alarm because it’s handling too much overflow traffic. You are then forced to make a second correction—but each correction means enduring another ten minutes or more in this long feedback loop.
Through such repeated fine-tuning and waiting, the system eventually stabilizes, albeit temporarily. Yet, the entire process not only demands constant attention to monitoring but also involves enduring the DNS propagation delay, anxiously waiting for each adjustment to take effect. Traffic has been rerouted, and services have held up, but this stability, achieved through manual, iterative trial and error, is a cumbersome process with significant risks, always feeling like walking on a tightrope. The problem is resolved, but the method of resolution seems far from ideal.
Traffic Instability Is Not a Configuration Problem
We often attribute such problems to “lack of experience” or “inadequate contingency plans.” However, as engineers, we should scrutinize the tools themselves: are existing scheduling tools genuinely suitable for handling these continuously evolving scenarios?
Consider some of our most commonly used scheduling tools: DNS weighting, health checks, and even simple GSLB. They share several common characteristics:
- Discrete: Weight values are static configurations, such as 80 or 70. They cannot express dynamic, continuous response strategies like “when node load reaches 75%, the weight smoothly decreases from 80 to 75.”
- Binary: The outcomes of health checks are typically binary – a simple pass or fail. A node is either online or offline; we cannot ascertain its “degraded” or “partially healthy” state, such as “the node is online, but response latency has started to soar.”
- Abrupt: Whether due to a health check failure or manually reducing the weight to 0, traffic switching is sudden and drastic. This abrupt change itself can impact user experience and other nodes.
When these tools were initially designed, their core assumption was that server states are relatively stable, and changes occur infrequently. Today, however, business elastic scaling, instantaneous traffic surges, and graceful service degradation have transformed system states into a continuously changing process. We are attempting to manage a continuously evolving system with “on/off” or discrete tools. This mismatch between tools and scenarios is precisely the root cause of the “instability” or “lack of confidence” experienced during operations.
Why Global Optimization Breaks Down Under Real Traffic
An ideal global traffic scheduling tool essentially boils down to three fundamental yet crucial requirements:
- Smooth Traffic Shifting: When a node’s load increases and it enters a “degraded” or “sub-healthy” state, the system should automatically and gradually reduce its traffic. This prevents the need for manual intervention or an abrupt “hard cut-off” only after the node becomes completely unavailable.
- Automatic Circuit Breaker: Should a node’s load exceed its safety threshold and it can no longer handle additional requests, the system must automatically and quickly isolate it. This involves stopping the distribution of new traffic to protect the node itself and the stability of the overall service.
- Observability and Traceability: All scheduling decisions, whether automated or manual, must be clearly recorded. This allows for retrospective auditing to understand precisely what the system did and the rationale behind its decisions at any given point in time.
These three points are not merely advanced technical specifications; rather, they reflect the core demands of engineers for production tools: automating repetitive, high-risk judgments while empowering engineers with ultimate control and full transparency.
Control Requires Feedback, Not Faster Reactions
OpenResty Edge’s GSLB functionality is specifically designed for this scenario. It aims to schedule traffic in a manner that is more responsive to real-time load changes: based on custom business metrics such as machine load and request rate, it dynamically redistributes traffic across different machines, and even across different clusters. Rather than simply asking “is the path up?”, it asks “can the business sustain this load?” — and proactively adjusts traffic routing accordingly.
Health Is a Capacity Question, Not a Connectivity Check
Traditional GSLB health checks primarily rely on Ping or port detection. These methods can only determine if a node is “alive,” but fail to assess its “service quality” or performance.
OpenResty Edge extends health checks from the network layer to the application layer, allowing users to define custom business metrics tailored to their own workload characteristics — metrics that more accurately reflect real operational pressure. The following are a few representative examples:
- Requests per second: The number of requests an application processes per second.
- Active connections: The current count of active connections.
- System load averages.
The significance of these custom business metrics is that they no longer merely ask whether a node is alive — they ask about its service capacity and health level. When the scheduling system can make decisions based on real business load, it can dynamically redistribute traffic to machines with lower load, or even shift traffic to an entirely different standby cluster — rather than reacting only after a node has already failed. We are not dismissing traditional approaches; we are simply acknowledging that in today’s complex operational environments, network-layer information alone is no longer enough.
Replacing Abrupt Failover with Gradual Load Shedding
To address “degraded performance” or “unhealthy” states, OpenResty Edge GSLB has introduced a “Watermark” model, replacing traditional single-threshold approaches.
- Low Watermark: When a node’s specific metric (e.g., CPU load) exceeds the low watermark, the system does not immediately take the node offline. Instead, it begins to proportionally reduce its traffic weight. This creates a buffer zone, allowing for a smooth, gradual reduction in traffic, giving the node an opportunity to recover and stabilize.
- High Watermark: When the metric continues to deteriorate and crosses the high watermark, the system triggers a circuit break. At this point, GSLB stops routing any new traffic to that node and automatically migrates its load to other healthy nodes within the same cluster, or schedules traffic across clusters to a geographically separate standby cluster — ensuring the node is not completely overwhelmed and that the overall service remains available.
The essence of this design is to prevent abrupt and disruptive traffic shifts between nodes. It emulates the decision-making process of an experienced engineer: first, a gentle degradation, followed by a decisive circuit break.
Explainability Is a Prerequisite for Trust, Not a UI Feature
In control systems, the higher the degree of automation, the more stringent the requirements for operational transparency. For a critical decision system like GSLB, which acts as a traffic ingress point, if operations personnel cannot understand the rationale behind its decisions through logs or dashboards, then this automation inherently poses an uncontrollable risk.
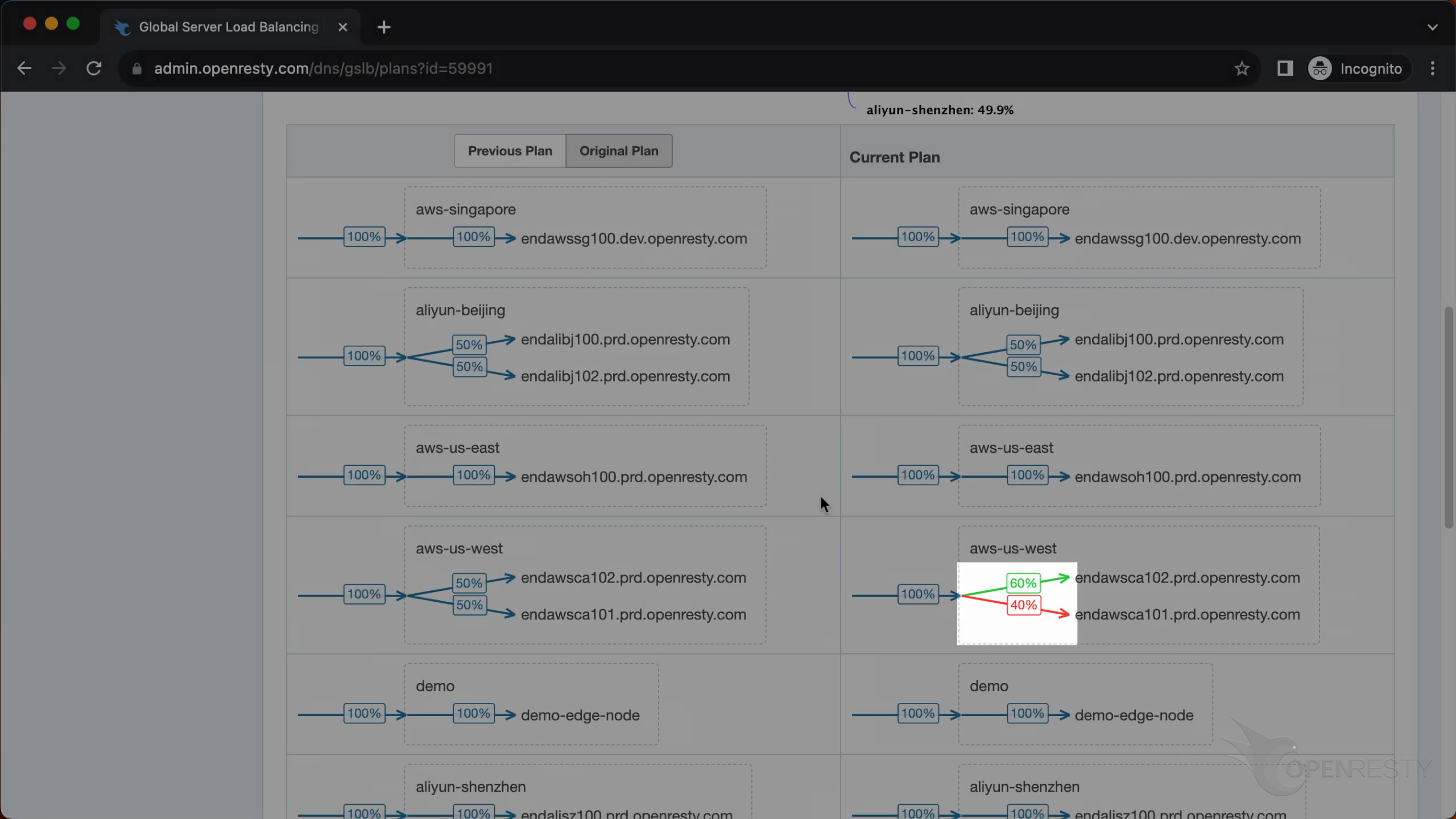
OpenResty Edge’s GSLB provides an intuitive visual dashboard that clearly answers the question “why schedule”:
- Plan Comparison: The system clearly visualizes the difference between the
original DNS planand theGSLB planafter GSLB’s intelligent adjustments. - Traffic Flow Changes: We quantify the direction and magnitude of traffic migration through visual indicators of weight changes. With prominent red and green arrows, you can instantly see which nodes are experiencing reduced traffic and which are seeing increased traffic. (Green indicates an increase, red indicates a decrease)
- Historical Playback: The system supports replaying scheduling snapshots from any historical moment. This allows for accurately restoring the global traffic distribution and scheduler decisions at the time of an incident.
Observability is not merely an additional feature of automation, but its fundamental prerequisite. Only when the decision-making process can be audited and explained can automated scheduling truly be integrated into the trusted components of a production environment.
From Human-in-the-Loop Alerts to Deterministic Traffic Control
With GSLB gaining application-aware capabilities, smooth scheduling, and transparent decision-making, the operational model for O&M teams transforms.
| Operations Scenario | Traditional Approach | OpenResty Edge GSLB |
|---|---|---|
| Detecting Load Anomalies | Manual monitoring of dashboards, human judgment | System automatically monitors application-layer metrics |
| Decision Response Time | Minutes to tens of minutes (manual judgment + action + DNS propagation) | Sub-second automatic response |
| Strategy Adjustment | Manual weight modification, experience-based trial and error | Automatic, gradual adjustment based on preset thresholds |
| Node Overload Protection | Removal after health check failure (already problematic) | Proactive circuit breaking when high thresholds are met (preventive) |
| Post-Mortem Analysis | Reconstructing from logs and memory | Complete, traceable decision history |
| On-Call Duty | Constant standby required to handle alerts | System automatically processes according to rules, reducing manual intervention |
The role of engineers shifts from passively responsive “executors” to proactive “strategists.” Their core responsibilities now include:
- Defining the business’s “health” model (selecting appropriate application-layer metrics).
- Defining the system’s intervention strategies (setting reasonable thresholds and circuit breaker conditions).
Scheduling logic is encoded and handed over to the control plane to complete a “probe-decide-act” closed loop within a millisecond timeframe. Compared to decision delays and misoperation risks inherent in manual intervention, systematic automated scheduling provides the predictability and reliability essential for robust engineering. This fundamentally liberates O&M teams from the constant battle against increasing system entropy, allowing them to shift their focus from temporary SSH-based fixes to the long-term governance of system architecture.
If your architecture faces the following complex challenges, this application-aware GSLB will demonstrate its significant value:
- Multi-region/Multi-cluster Deployment: This is a primary use case for GSLB, maximizing resource utilization and disaster recovery capabilities.
- Unpredictable Business Peaks: Frequent traffic spikes necessitate a system with fast, automatic, and elastic scheduling capabilities.
- Non-linear Traffic Bursts: When facing pulsed traffic, conventional feedback loops are often too slow. What’s needed is a control system that can instantly perceive and automatically execute degradation or peak-shaving strategies at the edge, rather than relying on alert-triggered manual processes.
Conclusion: The Technical Verdict
Let’s bring this to a technical close. OpenResty Edge GSLB shouldn’t be viewed as a centralized “brain” attempting to hijack decision-making authority. Instead, think of it as an application-aware runtime living at the edge. It operates strictly within the safety boundaries you define, utilizing tighter feedback loops to handle traffic fluctuations linearly—eliminating the jarring, “binary” switching inherent in traditional scheduling.
The core value of OpenResty Edge GSLB isn’t just about automation; it’s about banishing latency and coarseness from your system’s reaction to load changes. Ultimately, the granularity of your traffic governance defines the upper limit of your system’s stability.
Is your infrastructure struggling with rigid, “all-or-nothing” traffic policies?
If you are navigating cross-region challenges or high-concurrency spikes, don’t settle for brittle scheduling. Request for free and talk to our Solution Architects. Our expert team will dissect your specific scenario and demonstrate how to engineer smoother, more resilient traffic shaping with OpenResty Edge.
For a deep dive into the configuration logic and flexibility mentioned above, refer to our technical guide: How to Use Global Server Load Balancing (GSLB) in OpenResty Edge.
What is OpenResty Edge
OpenResty Edge is our all-in-one gateway software for microservices and distributed traffic architectures. It combines traffic management, private CDN construction, API gateway, security, and more to help you easily build, manage, and protect modern applications. OpenResty Edge delivers industry-leading performance and scalability to meet the demanding needs of high concurrency, high load scenarios. It supports scheduling containerized application traffic such as K8s and manages massive domains, making it easy to meet the needs of large websites and complex applications.
About The Author
Yichun Zhang (Github handle: agentzh), is the original creator of the OpenResty® open-source project and the CEO of OpenResty Inc..
Yichun is one of the earliest advocates and leaders of “open-source technology”. He worked at many internationally renowned tech companies, such as Cloudflare, Yahoo!. He is a pioneer of “edge computing”, “dynamic tracing” and “machine coding”, with over 22 years of programming and 16 years of open source experience. Yichun is well-known in the open-source space as the project leader of OpenResty®, adopted by more than 40 million global website domains.
OpenResty Inc., the enterprise software start-up founded by Yichun in 2017, has customers from some of the biggest companies in the world. Its flagship product, OpenResty XRay, is a non-invasive profiling and troubleshooting tool that significantly enhances and utilizes dynamic tracing technology. And its OpenResty Edge product is a powerful distributed traffic management and private CDN software product.
As an avid open-source contributor, Yichun has contributed more than a million lines of code to numerous open-source projects, including Linux kernel, Nginx, LuaJIT, GDB, SystemTap, LLVM, Perl, etc. He has also authored more than 60 open-source software libraries.
Related Articles
OpenResty XRay Nov 9, 2023
 Feature")
OpenResty XRay May 18, 2026

OpenResty XRay May 6, 2026

OpenResty XRay Apr 23, 2026

OpenResty XRay Apr 22, 2026












 Feature")


